배열과 슬라이스
Go에서 슬라이스 타입은 연속된 타입 데이터를 처리하는데 있어 편리하고 효과적 방법을 제공한다. 슬라이슨느 다른 언어에서 배열과 유사하지만 일부 다른 특징을 지니고 있다. 여기서는 슬라이스가 무엇이고 어떻게 사용하는지를 알아본다.
http://blog.golang.org/go-slices-usage-and-internals
배열 - Array
- 슬라이스 타입은 array 타입을 기반으로 그 위에 만들어진 추상화 타입이다. 따라서 슬라이스를 이해하기 위해서는 반드시 array 타입을 이해해야만 한다.
- array 타입 정의는 길이와 엘리먼트 타입을 지정한다. 에제로 [4]int는 4개 정수를 가지는 배열을 뜻한다. 배열의 크기는 고정되어 있다. 타입의 일부에 이미 길이가 포함되어 있다. ([4]int와 [5]int는 서로 다른 타입이며 호환되지 않는 타입이다.) 배열은 일반 방법으로 인덱스할 수 있다. 따라서 s[n] 표현으로 n번째 엘리먼트에 접근가능하면 인덱스는 0부터 시작한다.
var a [4]int
a[0] = 1
i := a[0]
//i == 1
- 배열은 명시적으로 초기화할 필요가 없다. 배열은 사용준비가 되면 이미 제로값으로 초기화 되어 있다.
// a[2] == 0, int 타입의 제로값을 가진다.
- [4]int의 메모리내에서는 4개 정수 값이 순차적으로 자리잡고 있다.

- Go에서 배열은 값이다. 배열 변수는 전체 배열을 나타낸다. 첫번째 배열 엘리먼트에 대한 포인터가 아니다. (C에서는 첫번째 배열 엘리먼트의 배열) 이 말은 배열 값을 할당하거나 전달할 때, 복사본을 전달한다는 뜻이다. 배열에 생각할 때는 필드 이름를 가지고 있는 대신 인덱스를 가지고 있는 구조체라고 보면 된다. 즉 고정길이의 composite 값이라 할 수 있다.
- 배열 리터럴은 아래와 같이 지정할 수 있다.
b := [2]string{"Penn", "Teller"}
- 여러분은 컴파일러에게 배열 엘리먼트의 수를 카운트하게 할 수 있다.
b := [...]string{"Penn", "Teller"} - 두 경우 모두 b의 타입은 [2]string이 된다.
슬라이스
- 배열은 자신의 공간을 가지지만 어떻게 보면 조금은 유연하지 못하다. 이런 이유로 실제 Go 코드에서 배열을 흔하게 보기 힘들다. 하지만 슬라이스는 여기저기 많이 쓰인다. 슬라이스는 배열을 기반으로 만들어져서 엄청난 기능과 편리함을 제공한다.
- 슬라이스 타입을 지정하는 방법은 []T이다. T가 의미하는 것은 슬라이스의 엘리먼트의 타입이다. 배열 타입과 달리 슬라이스 타입은 특정 길이를 가지지 않는다.
- 슬라이스 리터럴은 배열 리터럴과 비슷하게 선언하지만 엘리먼트 수를 나타내는 부분을 비워둔다.
letters := []string{"a", "b", "c", "d"}
- make 함수로 생성할 수도 있다.
func make([]T, len, cap) []T
- T가 의미하는 것은 생성할 슬라이스의 엘리먼트 타입이다. make 함수는 파라미터로 타입, 길이 그리고 선택적으로 용량을 가질 수 있다. 호출될 때, make는 배열을 할당하고 이 배열을 참조하는 슬라이스를 반환한다.
var s []byte
s = make([]byte, 5, 5)
//s == []byte{0, 0, 0, 0, 0}
- 용량 인자를 생략하면, 기본값으로 특정 길이로 설정된다. 동일한 코드의 간결한 버전은 아래와 같다.
s := make([]byte, 5)
- 슬라이스의 길이와 용량은 빌드인 함수인 len과 cap으로 확인할 수 있다.
len(s) == 5
cap(s) == 5
- 다음 2개 섹션에서는 길이와 용량 사이의 관계에 대해서 이야기하자.
- 슬라이스의 제로값은 nil이다. nil 슬라이스의 경우 len과 cap 함수가 반환하는 값은 0이다.
- 슬라이스는 기존 슬라이스와 배열을 조각내는 것과 동일하다. 조각낸 부분을 표현할 때 2개 인덱스를 사용하며 각 인덱스 구분은
:을 사용한다. b[1:4] 와 같은 표현은 1번째 인덱스에서 3번째 인덱스까지 값을 포함하는 슬라이슬르 생성한다. (결과로 나온 인덱스는 0에서 2까지 인덱스를 가진다.)
b := []byte{'g', 'o', 'l', 'a', 'n', 'g'}
// b[1:4] == []byte{'o', 'l', 'a'}
- 슬라이스에서 시작과 끝 인덱스 표현은 선태적으로 사용할 수 있다. 사용하지 않는 경우 시작 인덱스는 0이 되고 끝 인덱스는 슬라이스의 길이가 된다.
// b[:2] == []byte{'g', 'o'}
// b[2:] == []byte{'l', 'a', 'n', 'g'}
// b[:] == b
슬라이스 내부
- 슬라이스는 배열 세그먼트에 대해서 기술하고 있다. 배열에 대한 포인터, 세그먼트의 길이와 용량으로 구성된다.(세그먼트의 최대 길이가 용량이다.)

s 변수는 앞에서 make([]byte, 5)로 생성했다. 구조는 아래와 같다.
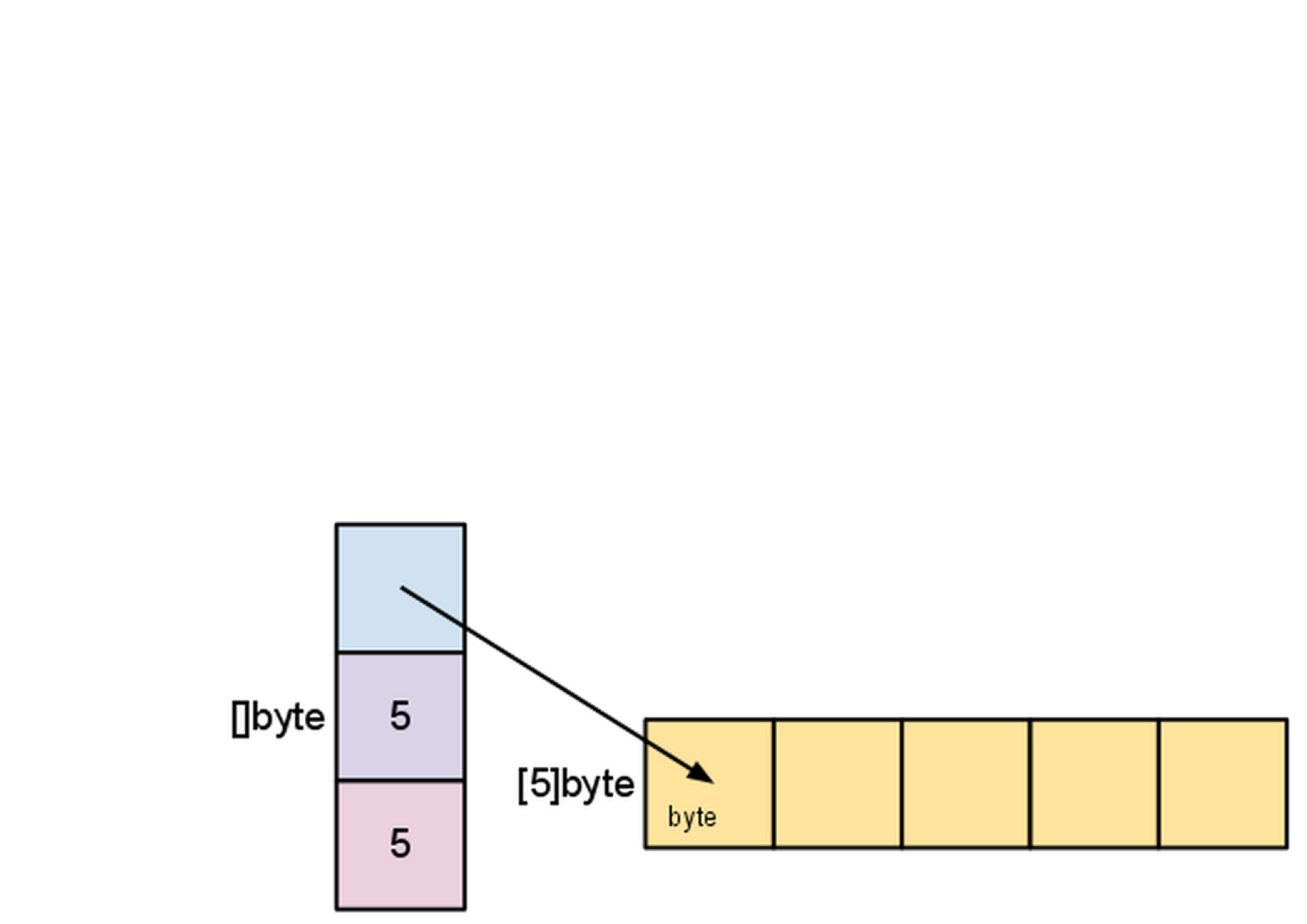
슬라이스가 가리키는 엘리먼트의 수가 바로 길이가 된다. 용량은 기반 배열의 엘리먼트의 수가 된다.(슬라이스 포인터가 가리크는 엘리먼트를 시작으로 봤을때) 길이와 용량의 차이는 다음 몇 가지 예제에서 확실히 알 수 있다.
- 슬라이스 s를 볼 때, 슬라이스 자료구조내에서 변경과 기반 배열과의 관계를 관찰하자.
s = s[2:4]
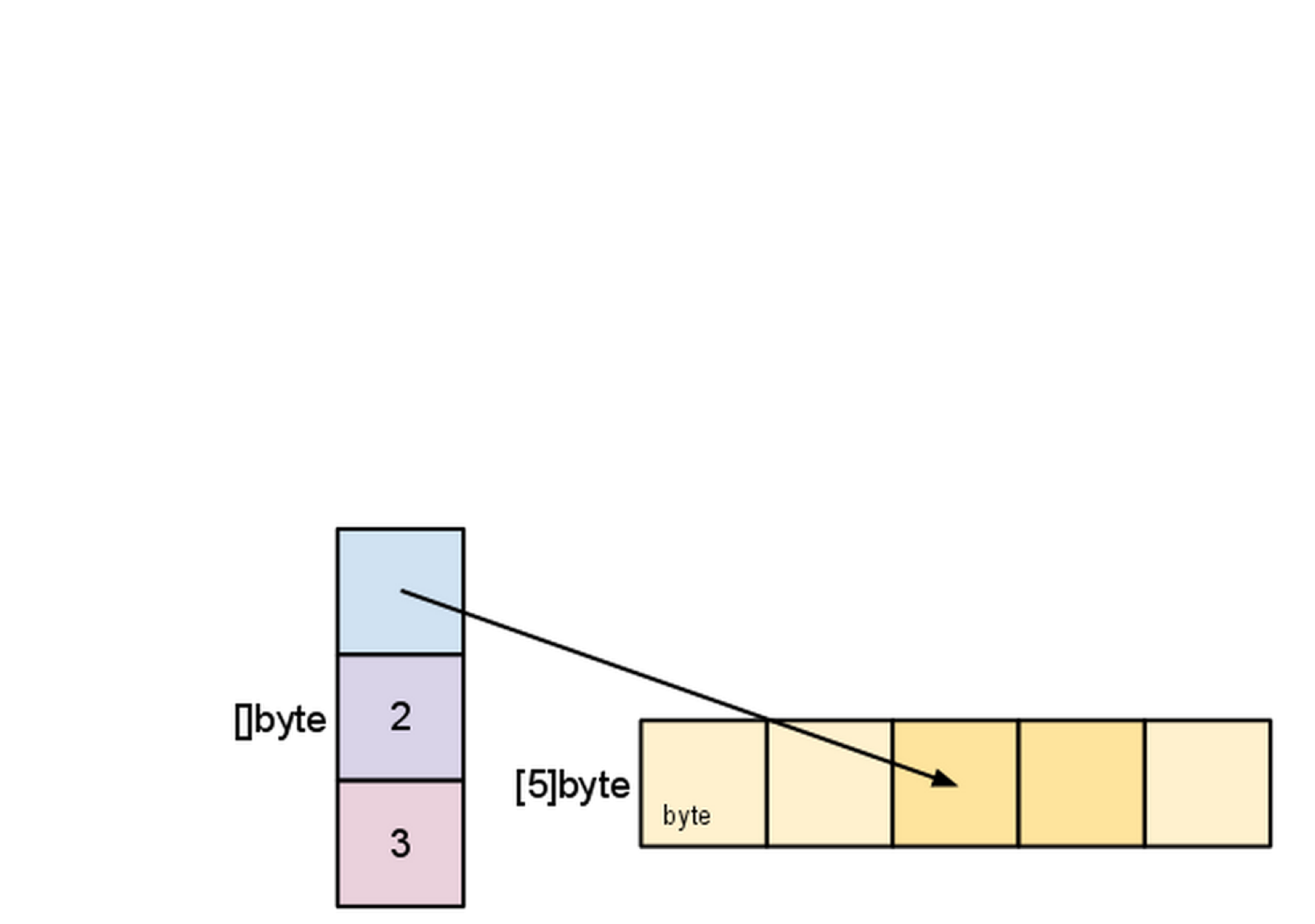
- 조각내기(슬라이싱)은 슬라이스의 데이터를 복사하지 않는다. 원본 배열을 가리키는 새로운 슬라이스 값을 생성한다. 이렇게 하면 슬라이스 연산은 배열에서 인덱스를 다루는 것만큼 효율적이 된다. 따라서 새로운 슬라이스의 엘리먼트를 변경하는 것은 원래 슬라이스의 엘리먼트를 수정하는 것과 같다.
d := []byte{'r', 'o', 'a', 'd'}
e := d[2:]
// e == []byte{'a', 'd'}
e[1] = 'm'
// e == []byte{'a', 'm'}
// d == []byte{'r', 'o', 'a', 'm'}
- 이전에 s를 어떤 길이로 조각내면 용량이 적어진다. 다시 이것을 조각내기를 하면 용량만큼 늘릴 수 있다.
s = s[:cap(s)]
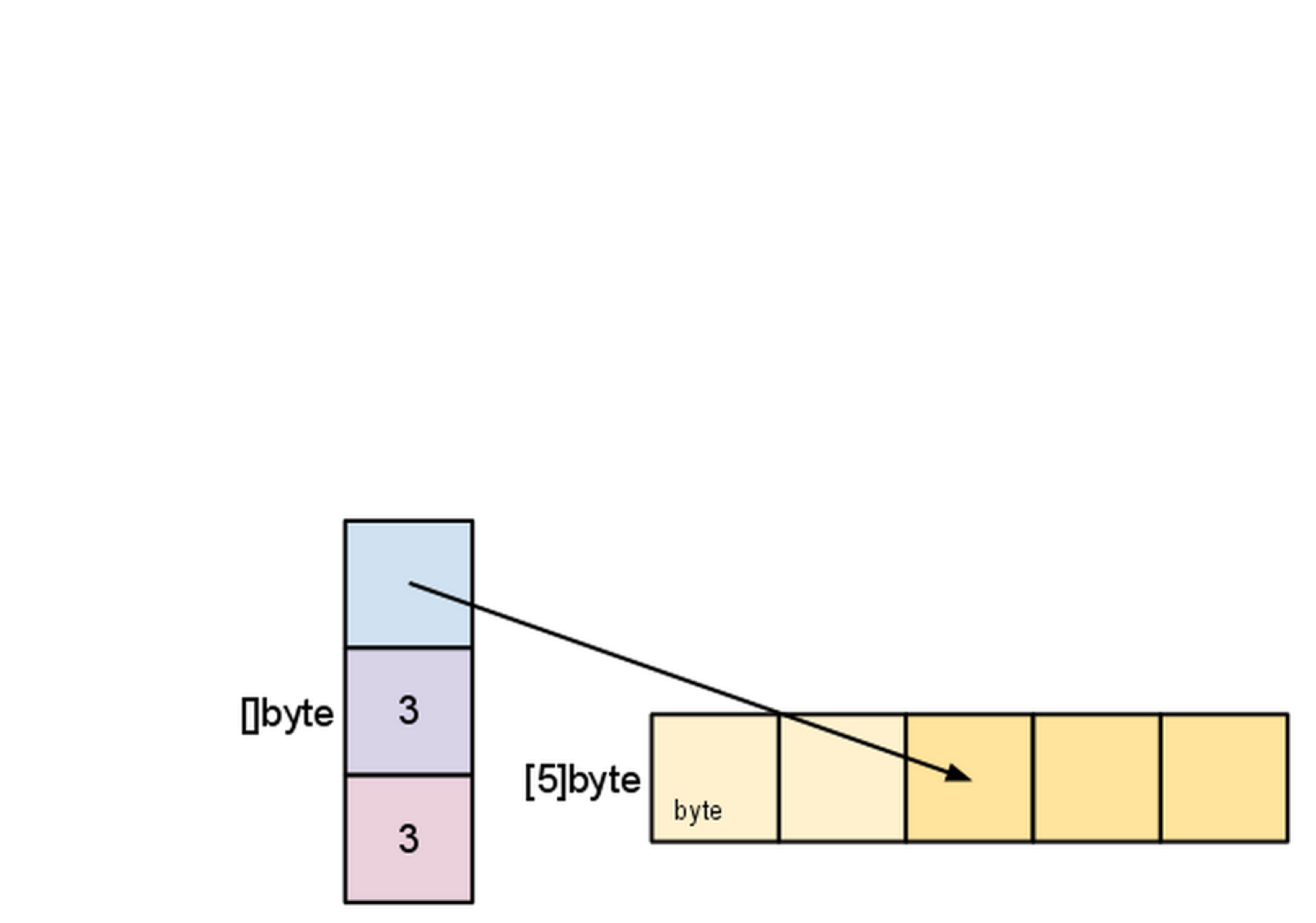
- 슬라이스는 용량보다 크게 늘릴 수는 없다. 더 늘릴려고 하면 런타임 패닉이 발생한다. 이는 마치 슬라이스나 배열에서 인덱스가 범위를 밖을 인덱스하는 경우와 같다. 유사하게 배열내에서 엘리먼트에 접근하기 위해서 슬라이스는 0보다 작게 조각내기 할 수 없다.
슬라이스 늘리기
- 슬라이스의 용량을 늘리기 위해서는 반드시 새로 더 큰 슬라이스를 생성해야 하고 원래 슬라이스의 내용물을 여기에 복사해야 한다. 이런 기술은 다른 언어에서 동적 배열 구현이 실제 뒤에서 동작하는 것과 비슷하다. 다음 예제에서 새로 슬라이스를 만들때 용량을 s 용량의 2배로 하며 s의 내용물을 t에 복사하며 슬라이스 값 t를 s에 할당한다.
t := make([]byte, len(s), (cap(s)+1)*2)
for i := range s {
t[i] = s[i]
}
s = t
- 루프 연산은 빌드인 함수인 copy로 대체할 수 있다. 이름에서 알수 있듯이 copy 함수는 소스 슬라이스에서 목적 슬라이스로 데이터를 복사한다. 반환되는 것은 복사된 엘리먼트의 갯수이다.
func copy(dst, src []T) int
- copy 함수는 길이가 다른 슬라이스 사이에서 복사를 지원한다.(더 적은 수의 엘리먼트까지 복사된다)
- 추가로 copy는 동일한 기반 배열을 공유한느 소스와 목적 슬라이스를 처리하며 제대로 오버랩되도록 처리한다.
- copy를 이용하면 위의 코드를 단순화 시킬 수 있다.
t := make[]byte, len(s), (cap(s)+1)*2)
copy(t, s)
s = t
- 흔한 연산 중에 하나가 슬라이스 끝에 데이터를 추가하는 것이다. 아래 함수는 byte 엘리먼트를 byte 타입의 슬라이스에 추가하며 만약 필요하다면 슬라이스가 늘어날 수도 있으며 갱신된 슬라이스 값을 반환한다.
func AppendByte(slice []byte, data ...byte) {
m := len(slice)
n := m + len(data)
if n > cap(slice) {
newSlice := make([]byte, (n+1)*2)
copy(newSlice, slice)
slice = newSlice
}
slice = slice[0:n]
copy(slice[m:n], data)
return slice
}
- AppendByte 사용하면 아래와 같다.
p := []byte{2, 3, 5}
p = AppendByte(p, 7, 11, 13)
//p == []byte(2, 3, 5, 7, 11, 13)
- AppendByte같은 함수를 사용하는 경우 장점은 슬라이스가 늘어나는 방식을 완전히 제어할 수 있다는 것이다. 프로그램의 특징에 따라서 크거나 작게 원하는대로 할당할 수 있고 재할당시 크기에 제약을 둘수도 있다.
- 하지만 대부분의 프로그램은 이런 제어가 필요가 없다. Go에서는 빌트인 함수로 append 함수를 제공한다. 대부분 경우 append만으로도 충분하다.
func append(s []T, x ...T) []T
- 슬라이스 s의 끝에 x 엘리먼트를 추가하고 더 큰 용량이 필요한 경우에는 슬라이스를 늘린다.
a := make([]int, 1)
a = append(a, 1, 2, 3)
a == []int{0, 1, 2, 3)
- 하나의 슬라이스를 다른 슬라이스에 추가하는 경우, 2번째 인자를 인자의 리스트로 확장하기 위해서
...을 사용한다.
a := []string{"John", "Paul"}
b := []string{"George", "Ringo", "Pete"}
a = append(a, b...) // append(a, b[0], b[1], b[2])와 동일하다.
// a == []string{"John", "Paul", "George", "Ringo", "Pete"}
- 슬라이스의 제로값은 길이가 0인 슬라이스와 같이 동작한다. 따라서 여러분은 슬라이스 변수를 선언하고 루프를 이용해서 추가할 수 있다.
func Filter(s []int, fn func(int) bool) []int {
var p []int
for _, v := range s {
if fn(v) {
p = append(p, v)
}
}
return p
}
가능한 gotcha
- 앞서 말했듯이 슬라이스를 다시 조각내는 것은 기본 배열을 복사하는 것이 아니다. 전체 배열은 더이상 참조가 일어나지 않을 때까지 메모리에 유지하고 있다. 결과적으로 이렇게 되면 조그마한 부분만 필요하더라도 프로그램이 메모리에 모든 데이터를 지니고 있게 된다. * 예로, FindDigits 함수는 파일을 메모리로 로드하고 연속 숫자로 검색된 첫번째 그룹에 대해서 새로운 슬라이스로 만들어서 반환한다.
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}
- 이 코드는 광고처럼 동작하지만 반환된 []byte는 전체 파일을 포함하는 배열을 가리킨다. 슬라이스는 원래 배열을 가리키므로 슬라이스가 가비지 콜렉터로 유지되는 한 배열을 해제할 수 있따. 파일에서 몇개 유용한 바이트가 메모리에 전체 파일 내용을 유지하게 만드는 것이다.
- 이 문제를 해결하기 위해서 반환하기 전에 관심있는 데이터만 새로 만든 슬라이스에 복사한다.
func CopyDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = digitRegexp.Find(b)
c := make([]byte, len(b))
copy(c, b)
return c
}
- 이 함수의 더 압축된 버전은 append 함수를 이용하는 것이다. 연습문제로 남겨둔다.
참고
- Effective Go
- Language Sepc
- assiciated helper function